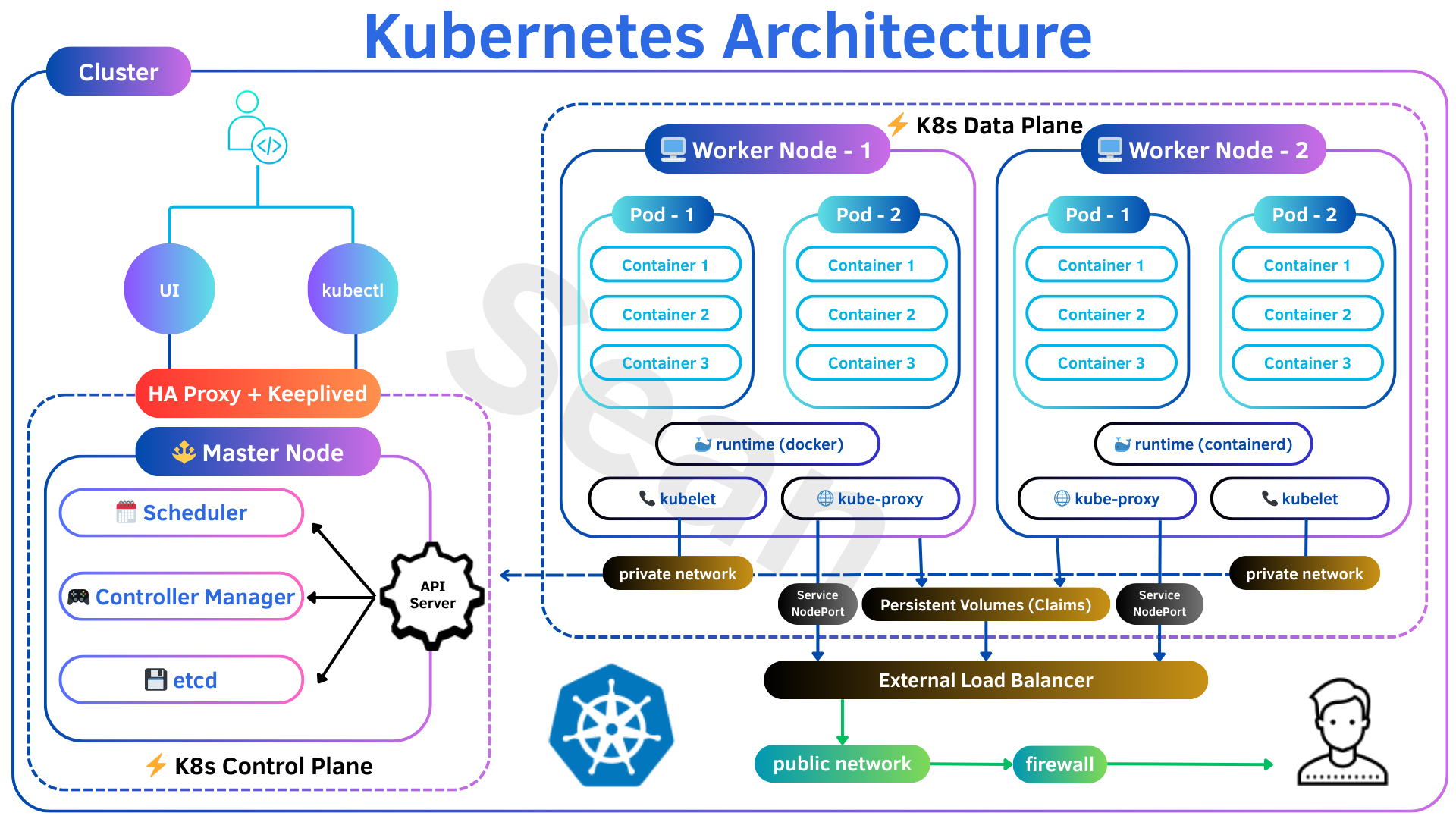
昨天簡單的自我介紹,以及探討 K8s 的強大之處,今天要來看看究竟 K8s 是如何運作的!
首先我們看到 Node (節點),Node 就是一台安裝了 K8s 的機器,可以是實體機器,也可以是虛擬機器,而 Container 就會被部署在 Node 上執行。
但想想看,如果只有一台 Node,萬一它掛了怎麼辦?我們的應用程式不就跟著掛了嗎?所以我們會需要多個 Node,這樣即使一個 Node 出問題,使用者還是可以從其他 Node 存取應用程式服務。而且多個 Node 也能分散流量,不會讓單一台機器被操爆。
這些 Node 組合起來,就叫做 Cluster(叢集)。
有了多個 Node 之後,新問題來了:系統要怎麼知道該把 Container 部署到哪個 Node?當 Node 掛掉時要怎麼轉移服務?誰來管理這一切?
這就是 Master Node 和 Worker Node 分工合作的時候了!
用樂團來比喻的話:
在安裝 Kubernetes 的同時以下有七個核心元件同時也會被安裝起來,如文章最一開始的架構圖可以看到分別是:API Server, etcd, Controller Manager, Scheduler, kubelet, kube-proxy, Container Runtime,讓我們來看看各個元件的功用是什麼吧!
API Server 是 K8s 唯一的存取入口,無論是我們開發用 kubectl 指令,還是 Cluster 內部的其他組件,甚至是使用者,都必須透過 API Server 來互動。它負責處理請求包含:驗證指令、認證授權等等,並將叢集的狀態資訊更新到 etcd 資料庫中。並且封裝了核心資源物件 (Pod, Service) 的 CRUD (新增、查詢、修改、刪除) 操作,透過 RESTFul 方式提供內外部元件使用。etcd 是 K8s 中非常重要的一部分,他儲存了所有資源物件的狀態資料,例如有多少個 Pod、運行了哪些應用、網路設定等。它是一個分散式儲存、高可用的 key-value NoSQL 資料庫 ,即使有多個 Master Node,也能確保資料同步,避免衝突。如果 Master Node 故障,可以透過 etcd 中儲存的資料來還原整個叢集的狀態。Controller Manager 猶如 Cluster 內部大腦。它內部運行著多種 Controller,例如 Replication Controller 負責確保 Pod 副本數量、Node Controller 負責監控節點狀態等。當它偵測到節點故障、Pod 意外終止時,會立即採取行動實現 Cluster 的「自癒」流程,確保 Cluster 始終處於預期的運作狀態。又或者某個 Pod 所在的 Worker Node 資源不足,Controller 會自動將 Pod 調度至其他資源充足的 Worker Node。Pod 時,Scheduler 的工作就是為這個 Pod 找到最適合的 Worker Node 來運行。它會評估各個 Worker Node 的資源使用情況(如 CPU、記憶體),並根據預設的調度演算法,將 Pod「綁定」到最合適的 Worker Node。Worker Node 皆會啟動 kubelet 服務, 用來處理 Master Node 對各節點所下達的任務。它會定期向 API Server 匯報自己所在節點的健康狀況,並接收來自 Master Node 的指令。當 Scheduler 決定將一個 Pod 部署到某個 Worker Node 時,就是由該節點上的 kubelet 負責確保 Pod 中的容器被正確啟動和運行。kube-proxy 一樣是運行在每個 Worker Node,他負責處理 Cluster 內的網路通訊。它管理著每個 Worker Node 上的網路規則(例如使用 iptables or IPVS),確保 Pod 之間、以及從外部存取 Service 時的網路流量能夠被正確路由到對應的 Pod。kubelet 透過它來管理容器的生命週期(啟動、停止等)。最廣為人知的 Container Runtime 就是 Docker,但 Kubernetes 也支援其他替代方案,如 CRI-O 或 containerd。沒有它,Worker Node 就無法真正運行容器。由上我們看出,Master Node 擁有 API Server, etcd, Controller Manager, Scheduler 四個組件。而 Worker Node 則是擁有 kubelet, kube-proxy, Container Runtime 三個組件。而 Master 和 Worker 的溝通是透過 API Server 和 kubelet 來進行互動。
講完了 Kubernetes 的核心元件之後,來看看我們要如何跟 Kubernetes 進行互動,主要工具就是 kubectl。他可以用來部署應用程式、查詢 Cluster 資訊、查看 Node 資訊等等。kubectl 支援兩種物件管理方式,Imperative (命令式) 和 Declarative (聲明式)。
# 在 default namespace 部署一個 Nginx Pod
kubectl run nginx --image=nginx
# 替 Pod 開一個 Service
kubectl expose pod nginx --port=80 --type=NodePort
# 再多開兩個副本
kubectl scale deployment nginx --replicas=3
# nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3 # 我想要三個副本
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
接著只需要執行指令:
kubectl apply -f nginx-deployment.yaml
上面講了一堆很抽象的東西,剛開始看 Kubernetes 的時候,整個超亂,完全不知道誰管誰或者各個元件之間的關係。後來我想說用一個真實情境來拆,像是「我要跑三個 Nginx」,照著流程走下來,就慢慢比較懂每個元件在幹嘛了 (可以參考下方流程圖):
kubectl 告訴 Master Node:我要 3 個 Nginx 實例etcd
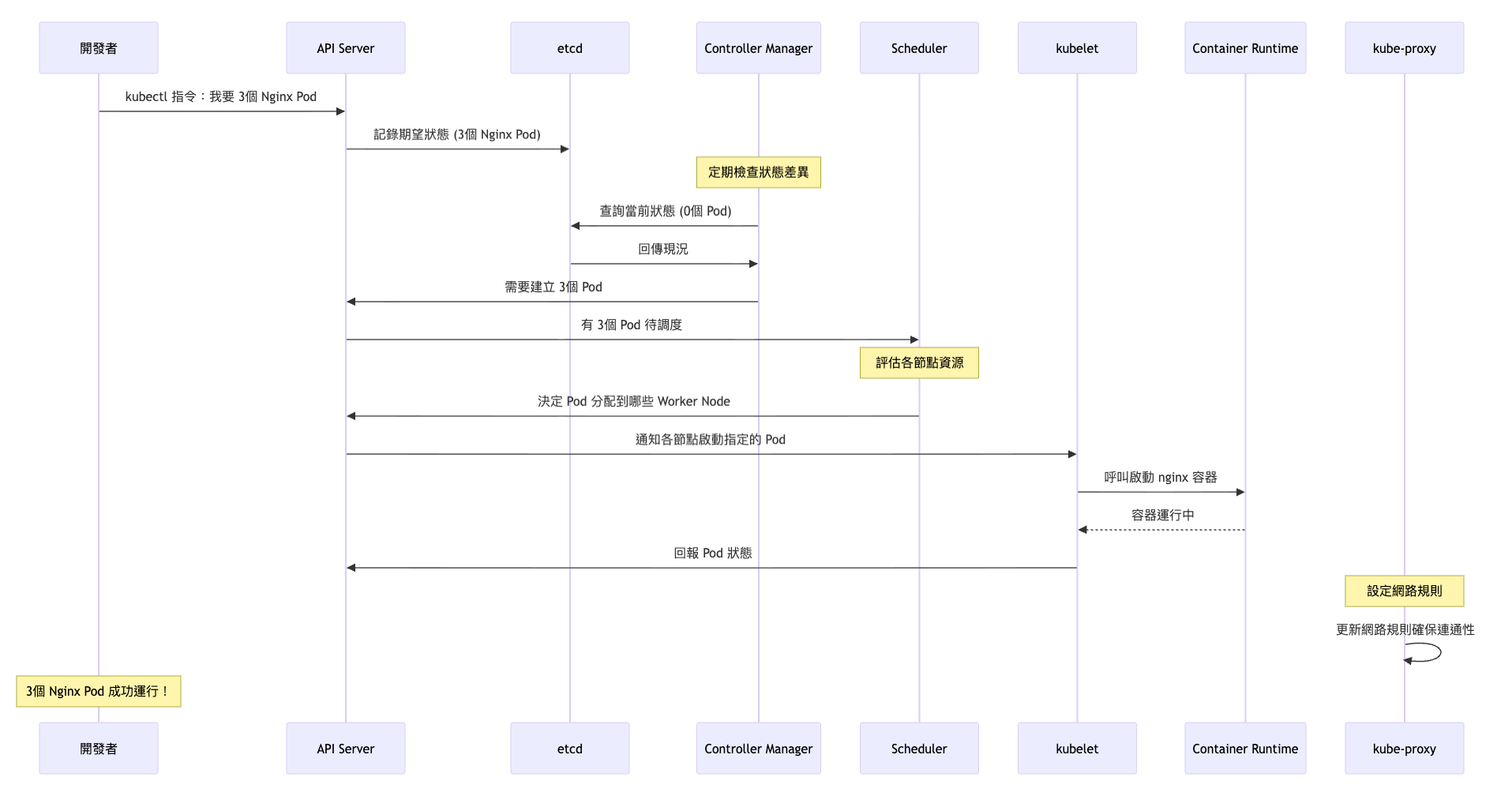
第一次看到 Kubernetes 裡那麼多組件的時候,每個名字聽起來都很重要。但一開始完全搞不清楚誰在負責什麼,也搞不懂各元件之間的關係。
直到後來拆解「從指令到執行」的整個過程,才驚覺原來一個簡單的 kubectl run 指令,背後牽扯到那麼多元件在默默協作,整個機制比想像中還要精細。
除了這些核心元件之外,前面提到了很多 K8s 的資源物件,像是 Pods、Deployment、Namespace、ReplicaSet、Service、PV、PVC 等等。這些名字一開始可能有點抽象,接下來會一個個遇到,也會實際操作,慢慢就能把它們串起來。
有趣的是,Kubernetes 真正管理的其實不是 Container 本身,而是一個叫 Pod 的東西。明天就要來好好認識這個 Kubernetes 的最小單位 - Pod。

